
你好,我是秦晓辉。
今天我们就正式开始监控系统的学习之旅了,作为课程的第一讲,我想先让你了解一下监控相关的背景信息,对监控系统有一个整体性的了解。所以今天我们会先聊一聊监控的需求来源,也就是说监控系统都可以用来做什么,然后再跳出监控,从可观测性来看,监控与日志、链路之间的关系以及它们各自的作用。最后我们会介绍开源社区几个有代表性的方案以及它们各自的优缺点,便于你之后做技术选型。
掌握这些背景信息,是我们学习监控系统的基础。下面我们就先来了解一下监控的需求来源。
最初始的需求,其实就是一句话:系统出问题了我们能及时感知到。当然,随着时代的发展,我们对监控系统提出了更多的诉求,比如:
目前监控系统越来越重要,同时也越来越完备。不但能够很好地解决上面这几点诉求,还沉淀出了很多监控系统中的稳定性相关的知识。当然,这得益于对监控体系的持续运营,特别是一些资深工程师的持续运营的成果。
我们所说的监控系统,其实只是指标监控,通常使用折线图形态呈现在图表上,比如某个机器的CPU利用率、某个数据库实例的流量或者网站的在线人数,都可以体现为随着时间而变化的趋势图。
指标监控只能处理数字,但它的历史数据存储成本较低,实时性好,生态庞大,是可观测性领域里最重要的一根支柱。聚焦在指标监控领域的开源产品有Zabbix、Open-Falcon、Prometheus、Nightingale等。
除了指标监控,另一个重要的可观测性支柱是日志。从日志中可以得到很多信息,对于了解软件的运行情况、业务的运营情况都很关键。比如操作系统的日志、接入层的日志、服务运行日志,都是重要的数据源。
从操作系统的日志中,可以得知很多系统级事件的发生;从接入层的日志中,可以得知有哪些域名、IP、URL 收到了访问,是否成功以及延迟情况等;从服务日志中可以查到 Exception 的信息,调用堆栈等,对于排查问题来说非常关键。但是日志数据通常量比较大,不够结构化,存储成本较高。
处理日志这个场景,也有很多专门的系统,比如开源产品ELK和Loki,商业产品Splunk和Datadog,下面是在 Kibana 中查询日志的一个页面。

可观测性最后一大支柱是链路追踪。随着微服务的普及,原本的单体应用被拆分成很多个小的服务,服务之间有错综复杂的调用关系,一个问题具体是哪个模块导致的,排查起来其实非常困难。
链路追踪的思路是以请求串联上下游模块,为每个请求生成一个随机字符串作为请求ID。服务之间互相调用的时候,把这个ID逐层往下传递,每层分别耗费了多长时间,是否正常处理,都可以收集起来附到这个请求ID上。后面追查问题时,拿着请求ID就可以把串联的所有信息提取出来。链路追踪这个领域也有很多产品,比如 Skywalking、Jaeger、Zipkin 等,都是个中翘楚。下面是Zipkin的一个页面。

虽然我们把可观测性领域划分成了3大支柱,但实际上它们之间是有很强的关联关系的。比如我们经常会从日志中提取指标,转存到指标监控系统,或者从日志中提取链路信息来做分析,这在业界都有很多实践。
我们这个课程会聚焦在指标监控领域,把这个领域的相关知识讲透,希望可以帮助你在工作中快速落地实践。下面我们就来一起梳理一下业界常见的开源解决方案。
了解业界典型方案的一些优缺点,对选型有很大帮助。这里我们主要是评价开源方案,其实业内还有很多商业方案,特别是像IBM Tivoli这种产品,更是在几十年前就出现了,但是因为是商业产品,接触的人相对较少,这里就不点评了。
Zabbix是一个企业级的开源解决方案,擅长设备、网络、中间件的监控。因为前几年使用的监控系统主要就是用来监控设备和中间件的,所以Zabbix在国内应用非常广泛。
Zabbix核心由两部分构成,Zabbix Server与可选组件Zabbix Agent。Zabbix Server可以通过SNMP、Zabbix Agent、JMX、IPMI等多种方式采集数据,它可以运行在Linux、Solaris、HP-UX、AIX、Free BSD、Open BSD、OS X等平台上。
Zabbix还有一些配套组件,Zabbix Proxy、Zabbix Java Gateway、Zabbix Get、Zabbix WEB等,共同组成了Zabbix整体架构。
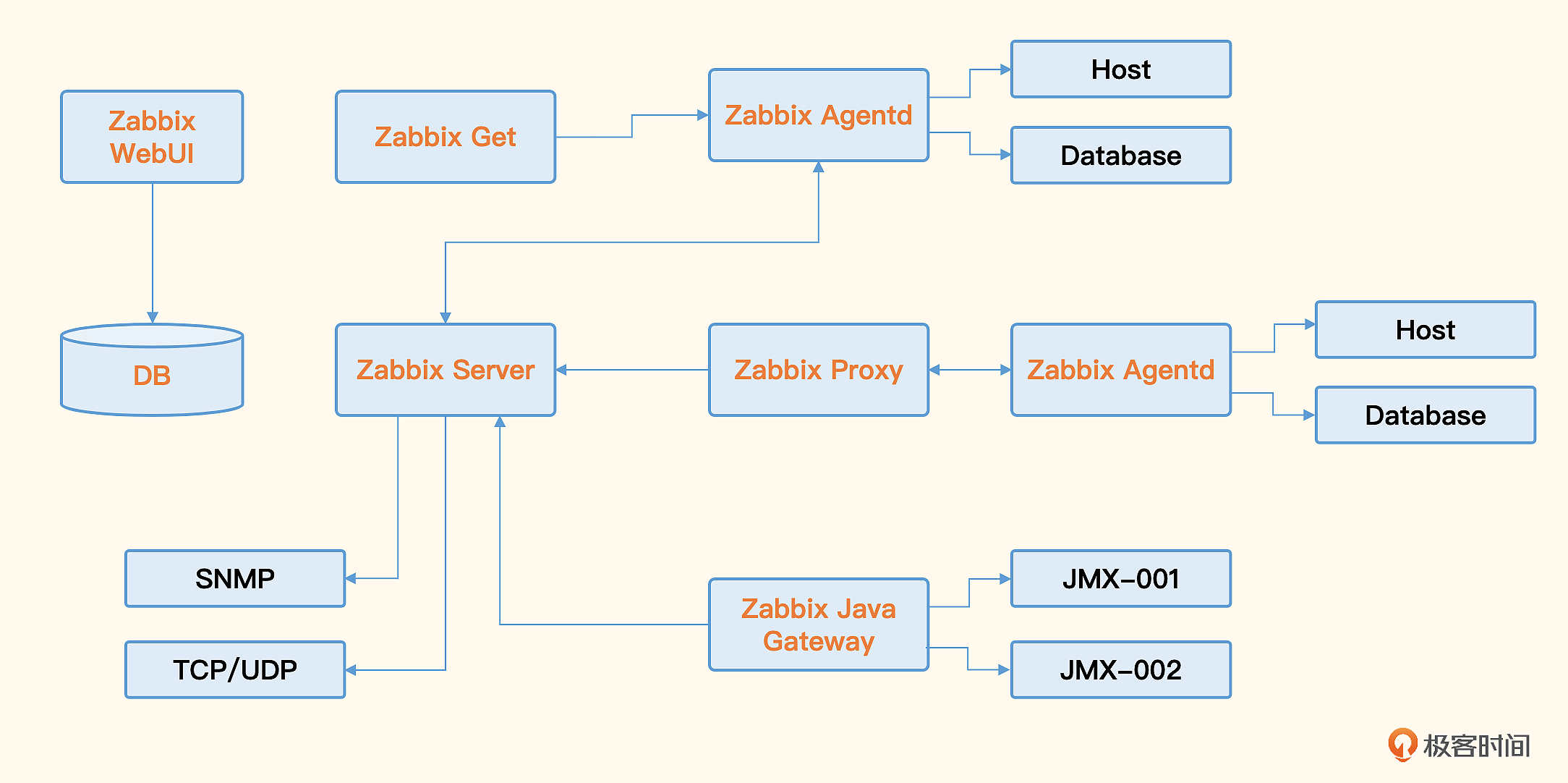
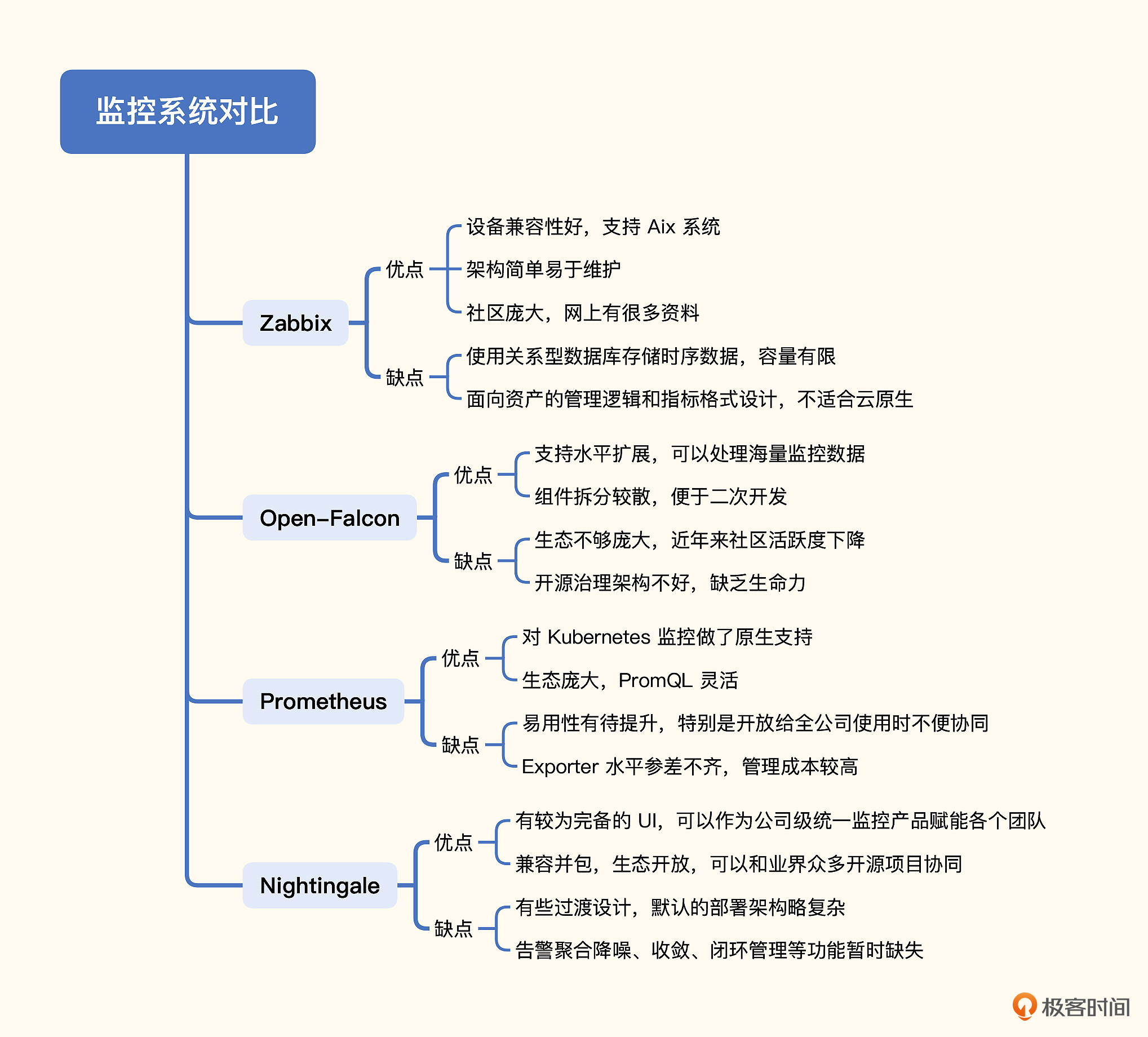
Zabbix的优点
Zabbix的缺点
Open-Falcon出现在Zabbix之后,开发的初衷就是想要解决Zabbix的容量问题。Open-Falcon最初来自小米,14年开源,当时小米有3套Zabbix,1套业务性能监控系统perfcounter。Open-Falcon的初衷是想做一套大一统的方案,来解决这个乱局。你可以看一下Open-Falcon的架构图。

Open-Falcon基于RRDtool做了一个分布式时序存储组件Graph。这种做法可以把多台机器组成一个集群,大幅提升海量数据的处理能力。前面负责转发的组件是Transfer,Transfer对监控数据求取一个唯一ID,再对ID做哈希,就可以生成监控数据和Graph实例的对应关系,这就是Open-Falcon架构中最核心的分片逻辑。
结合我们给出的架构图来看,告警部分是使用Judge模块来做的,发送告警事件的是Alarm模块,采集数据的是Agent,负责心跳的模块是HBS,负责聚合监控数据的模块是Aggregator,负责处理数据缺失的模块是Nodata。当然,还有用于和用户交互的Portal/Dashboard模块。
Open-Falcon把组件拆得比较散,组件比较多,部署起来相对比较麻烦。不过每个组件的职能单一,二次开发会比较容易,很多互联网公司都是基于Open-Falcon做了二次开发,比如美团、快网、360、金山云、新浪微博、爱奇艺、京东、SEA等。
Open-Falcon的优点
Open-Falcon的缺点
Prometheus的设计思路来自Google的Borgmon,师出名门,就像Borgmon是为Borg而生的,而Prometheus就是为Kubernetes而生的。它针对Kubernetes做了直接的支持,提供了多种服务发现机制,大幅简化了Kubernetes的监控。
在Kubernetes环境下,Pod创建和销毁非常频繁,监控指标生命周期大幅缩短,这导致类似Zabbix这种面向资产的监控系统力不从心,而且云原生环境下大都是微服务设计,服务数量变多,指标量也呈爆炸态势,这就对时序数据存储提出了非常高的要求。
Prometheus 1.0的版本设计较差,但从2.0开始,它重新设计了时序库,性能、可靠性都有大幅提升,另外社区涌现了越来越多的Exporter采集器,非常繁荣。你可以看一下Prometheus的架构图。

Prometheus的优点
Prometheus的缺点
Nightingale 可以看做是 Open-Falcon 的一个延续,因为开发人员是一拨人,不过两个软件的定位截然不同,Open-Falcon 类似 Zabbix,更多的是面向机器设备,而Nightingale 不止解决设备和中间件的监控,也希望能一并解决云原生环境下的监控问题。
但是在 Kubernetes 环境下,Prometheus 已经大行其道,再重复造轮子意义不大,所以 Nightingale 的做法是和 Prometheus 做良好的整合,打造一个更完备的方案。当下的架构,主要是把 Prometheus 当成一个时序库,作为 Nightingale 的一个数据源。如果不使用 Prometheus 也没问题,比如使用 VictoriaMetrics 作为时序库,也是很多公司的选择。

Nightingale的优点
Nightingale的缺点
上面我介绍了4种典型方案,每种方案各有优缺点,如果你的主要需求是监控设备,推荐你使用Zabbix;如果你的主要需求是监控Kubernetes,可以选择Prometheus+Grafana;如果你既要兼顾传统设备、中间件监控场景,又要兼顾Kubernetes,做成公司级方案,推荐你使用 Nightingale。
最后,我们来回顾一下这一讲的主要内容。
这一讲我们了解了监控产品的需求来源,即监控问题域,从最开始的一句话需求——及时感知系统出现的问题,到现在希望预知问题,并且可以洞察业务经营数据,越来越多的诉求让我们意识到监控的重要性。
指标监控是可观测性三大支柱产品之一,除了指标监控之外,还有日志监控和链路追踪。这三者并不是独立的,它们之间联系紧密,共同辅助我们衡量系统内外部的健康状况。其中指标监控因历史数据存储成本较低,实时性好,生态庞大,是可观测性领域里最重要的一根支柱,也是我们关注的重点。
最后我们对指标监控领域的多个开源解决方案做了横评对比,帮助你做技术方案的选型。针对指标监控的几个开源方案的优缺点比较,我做了一个脑图,帮助你对比记忆。
指标监控领域还有很多其他的解决方案,你还知道哪些其他产品?欢迎留言分享,你可以简单说一下产品名字、适用场景、优缺点,三个臭皮匠顶个诸葛亮,我们一起讨论,互相帮助。也欢迎你把今天的内容分享给你身边的朋友,邀他一起学习。我们下一讲再见!
点击加入课程交流群